Feature Preview
Overview
Samza 0.13.0 introduces a new programming model and a new deployment model. They’re being released as a preview because they represent major enhancements to how developers work with Samza, so it is beneficial for both early adopters and the Samza development community to experiment with the release and provide feedback. The following sections introduce the new features and link to tutorials which demonstrate how to use them. Please try them and send feedback to the dev mailing list
Try it Out
Want to skip all the details and get some hands on experience? There are three tutorials to help you get acquainted with running Samza applications in both YARN and embedded modes and programming with the high level API:
- Yarn Deployment - run a pre-existing Wikipedia application on YARN and observe the output.
- High Level API Code Walkthrough - walk through building the Wikipedia application, step by step.
- ZooKeeper Deployment - run a pre-existing Wikipedia application with ZooKeeper coordination and observe the output.
Architecture
Introduction
The Samza high level API provides a unified way to handle both streaming and batch data. You can describe the end-to-end application logic in a single program with operators like map, filter, window, and join to accomplish what previously required multiple jobs. The API is designed to be portable. The same application code can be deployed in batch or streaming modes, embedded or with a cluster manager environments, and can switch between Kafka, Kinesis, HDFS or other systems with a simple configuration change. This portability is enabled by a new architecture which is described in the sections below.
Concepts
The Samza architecture has been overhauled with distinct layers to handle each stage of application development. The following diagram shows an overview of Apache Samza architecture with the high level API.
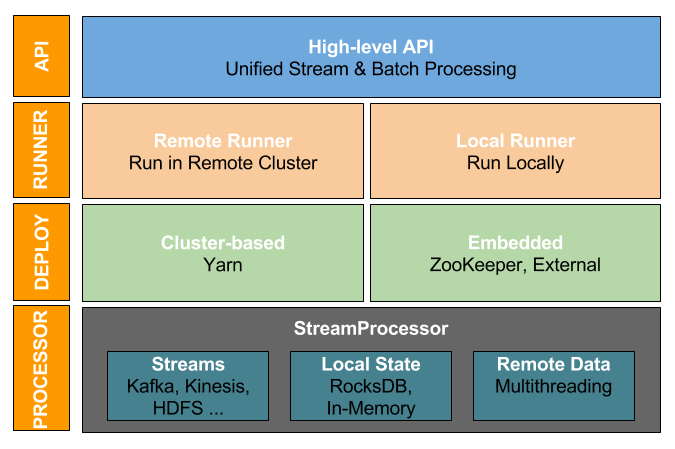
There are four layers in the architecture. The following sections describe each of the layers.
I. High Level API
The high level API provides the libraries to define your application logic. The StreamApplication is the central abstraction which your application must implement. You start by declaring your inputs as instances of MessageStream. Then you can apply operators on each MessageStream like map, filter, window, and join to define the whole end-to-end data processing in a single program.
For a deeper dive into the high level API, see high level API section below.
II. ApplicationRunner
Samza uses an ApplicationRunner to run a stream application. The ApplicationRunner generates the configs (such as input/output streams), creates intermediate streams, and starts the execution. There are two types of ApplicationRunner:
RemoteApplicationRunner - submits the application to a remote cluster. This runner is invoked via the run-app.sh script. To use RemoteApplicationRunner, set the following configurations
# The StreamApplication class to run
app.class=com.company.job.YourStreamApplication
job.factory.class=org.apache.samza.job.yarn.YarnJobFactoryThen use run-app.sh to run the application in the remote cluster. The script will invoke the RemoteApplicationRunner, which will launch one or more jobs using the factory specified with job.factory.class. Follow the yarn deployment tutorial to try it out.
LocalApplicationRunner - runs the application in the JVM process of the runner. For example, to launch your application on multiple machines using ZooKeeper for coordination, you can run multiple instances of LocalApplicationRunner on various machines. After the applications load they will start cordinatinating their actions through ZooKeeper. Here is an example to run the StreamApplication in your program using the LocalApplicationRunner:
public static void main(String[] args) throws Exception {
CommandLine cmdLine = new CommandLine();
Config config = cmdLine.loadConfig(cmdLine.parser().parse(args));
LocalApplicationRunner localRunner = new LocalApplicationRunner(config);
StreamApplication app = new YourStreamApplication();
localRunner.run(app);
// Wait for the application to finish
localRunner.waitForFinish();
System.out.println("Application completed with status " + localRunner.status(app));
}Follow the ZooKeeper deployment tutorial to try it out.
Execution Plan
The ApplicationRunner generates a physical execution plan for your processing logic before it starts executing it. The plan represents the runtime structure of the application. Particularly, it provides visibility into the generated intermediate streams. Once the job is deployed, the plan can be viewed as follows:
- For applications launched using run-app.sh, Samza will create a plan directory under your application deployment directory and write the plan.json file there.
- For the applications launched using your own script (e.g. for LocalApplicationRunner), please create a plan directory at the same level as bin, and point the
EXECUTION_PLAN_DIRenvironment variable to its location.
To view the plan, open the bin/plan.html file in a browser. Here’s a sample plan visualization:
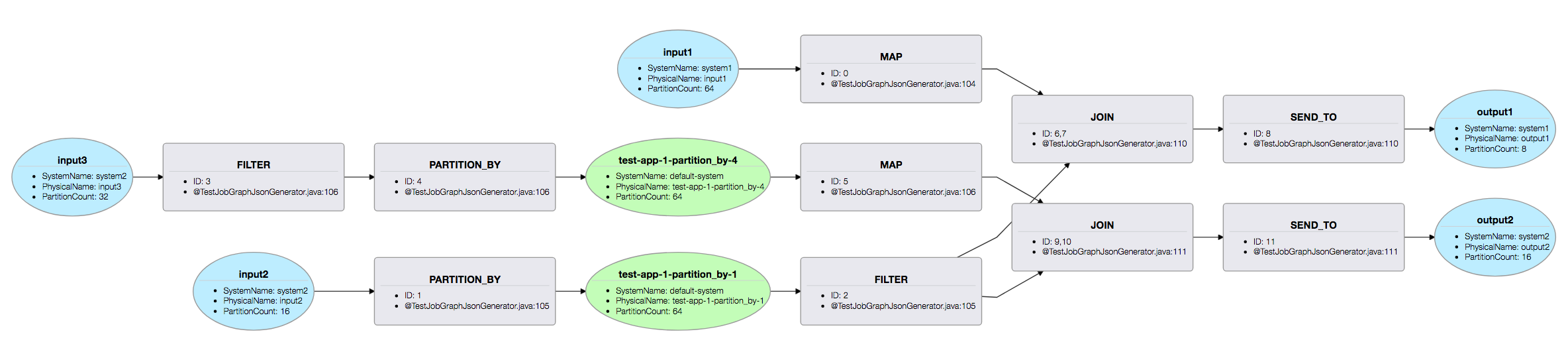
III. Execution Models
Samza supports two types of execution models: cluster based execution and embedded execution.
In cluster based execution, Samza will run and manage your application on a multi-tenant cluster. Samza ships with support for YARN. You can implement your own StreamJob and a corresponding ResourceManagerFactory to add support for another cluster manager.
In the embedded execution model, you can use Samza as a lightweight library within your application. You can spin up multiple instances of your application which will distribute and coordinate processing among themselves. This mode provides flexibility for running your applications in arbitrary hosting environments:It also supports pluggable coordination logic with out-of-the-box support for two types of coordination:
- ZooKeeper based coordination - Samza can be configured to use ZooKeeper to manage group membership and partition assignment among instances of your application. This allows the you to dynamically scale your application by spinning up more instances or scaling down by shutting some down.
- External coordination - Samza can run your application in a single JVM locally without coordination, or multiple JVMs with a static partition assignment. This is helpful when running in containerized environments like Kubernetes or Amazon ECS.
For more details on running Samza in embedded mode, take a look at the flexible deployment model section below.
IV. Processor
The lowest execution unit of a Samza application is the processor. It reads the configs generated from the ApplicationRunner and processes the input stream partitions assigned by the JobCoordinator. It can access local state using a KeyValueStore implementation (e.g. RocksDB or in-memory) and remote state (e.g. REST service) using multithreading.
High Level API
Since the 0.13.0 release, Samza provides a new high level API that simplifies your applications. This API supports operations like re-partitioning, windowing, and joining on streams. You can now express your application logic concisely in few lines of code and accomplish what previously required multiple jobs.
Code Examples
Check out some examples to see the high-level API in action.
- Pageview AdClick Joiner demonstrates joining a stream of PageViews with a stream of AdClicks, e.g. to analyze which pages get the most ad clicks.
- Pageview Repartitioner illustrates re-partitioning the incoming stream of PageViews.
- Pageview Sessionizer groups the incoming stream of events into sessions based on user activity.
- Pageview by Region counts the number of views per-region over tumbling time intervals.
Key Concepts
StreamApplication
When writing your stream processing application using the Samza high-level API, you should implement a StreamApplication and define your processing logic in the init method.
public void init(StreamGraph graph, Config config) { … }For example, here is a StreamApplication that validates and decorates page views with viewer’s profile information.
public class BadPageViewFilter implements StreamApplication {
@Override
public void init(StreamGraph graph, Config config) {
MessageStream<PageView> pageViews = graph.getInputStream(“page-views”, new JsonSerdeV2<>(PageView.class));
pageViews.filter(this::isValidPageView)
.map(this::addProfileInformation)
.sendTo(graph.getOutputStream(“decorated-page-views”, new JsonSerdeV2<>(DecoratedPageView.class)))
}
}MessageStream
A MessageStream, as the name implies, represents a stream of messages. A StreamApplication is described as a series of transformations on MessageStreams. You can get a MessageStream in two ways:
-
Using StreamGraph.getInputStream to get the MessageStream for a given input stream (e.g., a Kafka topic).
-
By transforming an existing MessageStream using operations like map, filter, window, join etc.
Anatomy of a typical Samza StreamApplication
There are 3 simple steps to write your stream processing applications using the Samza high-level API.
Step 1: Obtain the input streams:
You can obtain the MessageStream for your input stream ID (“page-views”) using StreamGraph.getInputStream.
MessageStream<PageView> pageViewInput = graph.getInputStream(“page-views”, new JsonSerdeV2<>(PageView.class));
The first parameter page-views is the logical stream ID. Each stream ID is associated with a physical name and a system. By default, Samza uses the stream ID as the physical stream name and accesses the stream on the default system which is specified with the property “job.default.system”. However, the physical name and system properties can be overridden in configuration. For example, the following configuration defines the stream ID “page-views” as an alias for the PageViewEvent topic in a local Kafka cluster.
streams.page-views.samza.system=kafka
systems.kafka.samza.factory=org.apache.samza.system.kafka.KafkaSystemFactory
systems.kafka.consumer.zookeeper.connect=localhost:2181
systems.kafka.producer.bootstrap.servers=localhost:9092
streams.page-views.samza.physical.name=PageViewEventThe second parameter is a serde to de-serialize the incoming message.
Step 2: Define your transformation logic:
You are now ready to define your StreamApplication logic as a series of transformations on MessageStreams.
MessageStream<DecoratedPageViews> decoratedPageViews
= pageViewInput.filter(this::isValidPageView)
.map(this::addProfileInformation);Step 3: Write the output to an output stream:
Finally, you can create an OutputStream using StreamGraph.getOutputStream and send the transformed messages through it.
// Send messages with userId as the key to “decorated-page-views”.
decoratedPageViews.sendTo(
graph.getOutputStream(“decorated-page-views”,
new JsonSerdeV2<>(DecoratedPageView.class)));The first parameter decorated-page-views is a logical stream ID. The properties for this stream ID can be overridden just like the stream IDs for input streams. For example:
streams.decorated-page-views.samza.system=kafka
streams.decorated-page-views.samza.physical.name=DecoratedPageViewEventThe second parameter is a serde to de-serialize the outgoing message.
Operators
The high level API supports common operators like map, flatmap, filter, merge, joins, and windowing on streams. Most of these operators accept corresponding Functions and these functions are Initable.
Map
Applies the provided 1:1 MapFunction to each element in the MessageStream and returns the transformed MessageStream. The MapFunction takes in a single message and returns a single message (potentially of a different type).
MessageStream<Integer> numbers = ...
MessageStream<Integer> tripled= numbers.map(m -> m * 3)
MessageStream<String> stringified = numbers.map(m -> String.valueOf(m))Flatmap
Applies the provided 1:n FlatMapFunction to each element in the MessageStream and returns the transformed MessageStream. The FlatMapFunction takes in a single message and returns zero or more messages.
MessageStream<String> sentence = ...
// Parse the sentence into its individual words splitting by space
MessageStream<String> words = sentence.flatMap(sentence ->
Arrays.asList(sentence.split(“ ”))Filter
Applies the provided FilterFunction to the MessageStream and returns the filtered MessageStream. The FilterFunction is a predicate that specifies whether a message should be retained in the filtered stream. Messages for which the FilterFunction returns false are filtered out.
MessageStream<String> words = ...
// Extract only the long words
MessageStream<String> longWords = words.filter(word -> word.size() > 15);
// Extract only the short words
MessageStream<String> shortWords = words.filter(word -> word.size() < 3);PartitionBy
Re-partitions this MessageStream using the key returned by the provided keyExtractor and returns the transformed MessageStream. Messages are sent through an intermediate stream during repartitioning.
MessageStream<PageView> pageViews = ...
// Repartition pageView by userId.
MessageStream<KV<String, PageView>> partitionedPageViews =
pageViews.partitionBy(pageView -> pageView.getUserId(), // key extractor
pageView -> pageView, // value extractor
KVSerde.of(new StringSerde(), new JsonSerdeV2<>(PageView.class)), // serdes
"partitioned-page-views") // operator ID
The operator ID should be unique for an operator within the application and is used to identify the streams and stores created by the operator.Merge
Merges the MessageStream with all the provided MessageStreams and returns the merged stream.
MessageStream<ServiceCall> serviceCall1 = ...
MessageStream<ServiceCall> serviceCall2 = ...
// Merge individual “ServiceCall” streams and create a new merged MessageStream
MessageStream<ServiceCall> serviceCallMerged = serviceCall1.merge(serviceCall2)The merge transform preserves the order of each MessageStream, so if message m1 appears before m2 in any provided stream, then, m1 also appears before m2 in the merged stream.
As an alternative to the merge instance method, you also can use the MessageStream#mergeAll static method to merge MessageStreams without operating on an initial stream.
SendTo (stream)
Sends all messages from this MessageStream to the provided OutputStream. You can specify the key and the value to be used for the outgoing message.
// Output a new message with userId as the key and region as the value to the “user-region” stream.
MessageStream<PageView> pageViews = ...
MessageStream<KV<String, PageView>> keyedPageViews = pageViews.map(KV.of(pageView.getUserId(), pageView.getRegion()));
OutputStream<KV<String, String>> userRegions
= graph.getOutputStream(“user-region”,
KVSerde.of(new StringSerde(), new StringSerde()));
keyedPageViews.sendTo(userRegions);SendTo (table)
Sends all messages from this MessageStream to the provided table, the expected message type is KV.
// Write a new message with memberId as the key and profile as the value to a table.
streamGraph.getInputStream("Profile", new NoOpSerde<Profile>())
.map(m -> KV.of(m.getMemberId(), m))
.sendTo(table);Sink
Allows sending messages from this MessageStream to an output system using the provided SinkFunction.
This offers more control than sendTo since the SinkFunction has access to the MessageCollector and the TaskCoordinator. For instance, you can choose to manually commit offsets, or shut-down the job using the TaskCoordinator APIs. This operator can also be used to send messages to non-Samza systems (e.g. remote databases, REST services, etc.)
// Repartition pageView by userId.
MessageStream<PageView> pageViews = ...
pageViews.sink( (msg, collector, coordinator) -> {
// Construct a new outgoing message, and send it to a kafka topic named TransformedPageViewEvent.
collector.send(new OutgoingMessageEnvelope(new SystemStream(“kafka”,
“TransformedPageViewEvent”), msg));
} )Join (stream-stream)
The stream-stream Join operator joins messages from two MessageStreams using the provided pairwise JoinFunction. Messages are joined when the keys extracted from messages from the first stream match keys extracted from messages in the second stream. Messages in each stream are retained for the provided ttl duration and join results are emitted as matches are found.
// Joins a stream of OrderRecord with a stream of ShipmentRecord by orderId with a TTL of 20 minutes.
// Results are produced to a new stream of FulfilledOrderRecord.
MessageStream<OrderRecord> orders = …
MessageStream<ShipmentRecord> shipments = …
MessageStream<FulfilledOrderRecord> shippedOrders = orders.join(shipments, new OrderShipmentJoiner(),
new StringSerde(), // serde for the join key
new JsonSerdeV2<>(OrderRecord.class), new JsonSerdeV2<>(ShipmentRecord.class), // serde for both streams
Duration.ofMinutes(20), // join TTL
"shipped-order-stream") // operator ID
// Constructs a new FulfilledOrderRecord by extracting the order timestamp from the OrderRecord and the shipment timestamp from the ShipmentRecord.
class OrderShipmentJoiner implements JoinFunction<String, OrderRecord, ShipmentRecord, FulfilledOrderRecord> {
@Override
public FulfilledOrderRecord apply(OrderRecord message, ShipmentRecord otherMessage) {
return new FulfilledOrderRecord(message.orderId, message.orderTimestamp, otherMessage.shipTimestamp);
}
@Override
public String getFirstKey(OrderRecord message) {
return message.orderId;
}
@Override
public String getSecondKey(ShipmentRecord message) {
return message.orderId;
}
}Join (stream-table)
The stream-table Join operator joins messages from a MessageStream using the provided StreamTableJoinFunction. Messages from the input stream are joined with record in table using key extracted from input messages. The join function is invoked with both the message and the record. If a record is not found in the table, a null value is provided; the join function can choose to return null (inner join) or an output message (left outer join). For join to function properly, it is important to ensure the input stream and table are partitioned using the same key as this impacts the physical placement of data.
streamGraph.getInputStream("PageView", new NoOpSerde<PageView>())
.partitionBy(PageView::getMemberId, v -> v, "p1")
.join(table, new PageViewToProfileJoinFunction())
...1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class PageViewToProfileJoinFunction implements StreamTableJoinFunction
<Integer, KV<Integer, PageView>, KV<Integer, Profile>, EnrichedPageView> {
@Override
public EnrichedPageView apply(KV<Integer, PageView> m, KV<Integer, Profile> r) {
return r != null ?
new EnrichedPageView(...)
: null;
}
@Override
public Integer getMessageKey(KV<Integer, PageView> message) {
return message.getKey();
}
@Override
public Integer getRecordKey(KV<Integer, Profile> record) {
return record.getKey();
}
}
Window
Windowing Concepts
Windows, Triggers, and WindowPanes: The window operator groups incoming messages in the MessageStream into finite windows. Each emitted result contains one or more messages in the window and is called a WindowPane.
A window can have one or more associated triggers which determine when results from the window are emitted. Triggers can be either early triggers that allow emitting results speculatively before all data for the window has arrived, or late triggers that allow handling late messages for the window.
Aggregator Function: By default, the emitted WindowPane will contain all the messages for the window. Instead of retaining all messages, you typically define a more compact data structure for the WindowPane and update it incrementally as new messages arrive, e.g. for keeping a count of messages in the window. To do this, you can provide an aggregating FoldLeftFunction which is invoked for each incoming message added to the window and defines how to update the WindowPane for that message.
Accumulation Mode: A window’s accumulation mode determines how results emitted from a window relate to previously emitted results for the same window. This is particularly useful when the window is configured with early or late triggers. The accumulation mode can either be discarding or accumulating.
A discarding window clears all state for the window at every emission. Each emission will only correspond to new messages that arrived since the previous emission for the window.
An accumulating window retains window results from previous emissions. Each emission will contain all messages that arrived since the beginning of the window.
Window Types:
The Samza high-level API currently supports tumbling and session windows.
Tumbling Window: A tumbling window defines a series of contiguous, fixed size time intervals in the stream.
Examples:
// Group the pageView stream into 3 second tumbling windows keyed by the userId.
MessageStream<PageView> pageViews = ...
MessageStream<WindowPane<String, Collection<PageView>>> =
pageViews.window(
Windows.keyedTumblingWindow(pageView -> pageView.getUserId(), // key extractor
Duration.ofSeconds(30), // window duration
new StringSerde(), new JsonSerdeV2<>(PageView.class)));
// Compute the maximum value over tumbling windows of 3 seconds.
MessageStream<Integer> integers = …
Supplier<Integer> initialValue = () -> Integer.MIN_VALUE;
FoldLeftFunction<Integer, Integer> aggregateFunction = (msg, oldValue) -> Math.max(msg, oldValue);
MessageStream<WindowPane<Void, Integer>> windowedStream =
integers.window(Windows.tumblingWindow(Duration.ofSeconds(30), initialValue, aggregateFunction, new IntegerSerde()));Session Window: A session window groups a MessageStream into sessions. A session captures a period of activity over a MessageStream and is defined by a gap. A session is closed and results are emitted if no new messages arrive for the window for the gap duration.
Examples:
// Sessionize a stream of page views, and count the number of page-views in a session for every user.
MessageStream<PageView> pageViews = …
Supplier<Integer> initialValue = () -> 0
FoldLeftFunction<PageView, Integer> countAggregator = (pageView, oldCount) -> oldCount + 1;
Duration sessionGap = Duration.ofMinutes(3);
MessageStream<WindowPane<String, Integer> sessionCounts = pageViews.window(Windows.keyedSessionWindow(
pageView -> pageView.getUserId(), sessionGap, initialValue, countAggregator,
new StringSerde(), new IntegerSerde()));
// Compute the maximum value over tumbling windows of 3 seconds.
MessageStream<Integer> integers = …
Supplier<Integer> initialValue = () -> Integer.MAX_INT
FoldLeftFunction<Integer, Integer> aggregateFunction = (msg, oldValue) -> Math.max(msg, oldValue)
MessageStream<WindowPane<Void, Integer>> windowedStream =
integers.window(Windows.tumblingWindow(Duration.ofSeconds(3), initialValue, aggregateFunction,
new IntegerSerde()))Table
A Table represents a dataset that can be accessed by keys, and is one of the building blocks of the Samza high level API; the main motivation behind it is to support stream-table joins. The current K/V store is leveraged to provide backing store for local tables. More variations such as direct access and composite tables will be supported in the future. The usage of a table typically follows three steps:
- Create a table
- Populate the table using the sendTo() operator
- Join a stream with the table using the join() operator
1
2
3
4
5
final StreamApplication app = (streamGraph, cfg) -> {
Table<KV<Integer, Profile>> table = streamGraph.getTable(new InMemoryTableDescriptor("t1")
.withSerde(KVSerde.of(new IntegerSerde(), new ProfileJsonSerde())));
...
};
Example above creates a TableDescriptor object, which contains all information about a table. The currently supported table types are InMemoryTableDescriptor and RocksDbTableDescriptor. Notice the type of records in a table is KV, and Serdes for both key and value of records needs to be defined (line 4). Additional parameters can be added based on individual table types.
More details about step 2 and 3 can be found at operator section.
Flexible Deployment Model
Introduction
Prior to Samza 0.13.0, Samza only supported cluster-managed deployment with YARN.
With Samza 0.13.0, the deployment model has been simplified and decoupled from YARN. If you prefer cluster management, you can still use YARN or you can implement your own extension to deploy Samza on other cluster management systems. But what if you want to avoid cluster management systems altogether?
Samza now ships with the ability to deploy applications as a simple embedded library with pluggable coordination. With embedded mode, you can leverage Samza processors directly in your application and deploy it in whatever way you prefer. Samza has a pluggable job coordinator layer to perform leader election and assign work to the processors.
This section will focus on the new embedded deployment capability.
Concepts
Let’s take a closer look at how embedded deployment works.
The architecture section above provided an overview of the layers that enable the flexible deployment model. The new embedded mode comes into the picture at the deployment layer. The deployment layer includes assignment of input partitions to the available processors.
There are two types of partition assignment models which are controlled with the job.coordinator.factory in configuration:
External Partition Management
With external partition management, Samza doesn’t manage the partitioning by itself. Instead it uses a PassthroughJobCoordinator which honors whatever partition mapping is provided by the SystemStreamPartitionGrouper. There are two common patterns for external partition management:
- Using high level Kafka consumer - partition assignment is done by the high level Kafka consumer itself. To use this model, you need to implement and configure a SystemFactory which provides the Kafka high level consumer. Then you need to configure job.systemstreampartition.grouper.factory to org.apache.samza.container.grouper.stream.AllSspToSingleTaskGrouper so Kafka’s partition assignments all go to one task.
- Customized partitioning - partition assignment is done with a custom grouper. The grouper logic is completely up to you. A practical example of this model is to implement a custom grouper which reads static partition assignments from the configuration.
Samza ships with a PassthroughJobCoordinatorFactory which facilitates this type of partition management.
Dynamic Partition Management
With dynamic partitioning, partitions are distributed between the available processors at runtime. If the number of available processors changes (for example, if some are shut down or added) the mapping will be regenerated and re-distributed to all the processors. Information about current mapping is contained in a special structure called the JobModel. There is one leader processor which generates the JobModel and distributes it to the other processors. The leader is determined by a “leader election” process.
Let’s take a closer look at how dynamic coordination works.
Coordination service
Dynamic coordination of the processors assumes presence of a coordination service. The main responsibilities of the service are:
- Leader Election - electing a single processor, which will be responsible for JobModel calculation and distribution or for intermediate streams creation.
- Central barrier and latch - coordination primitives used by the processors.
- JobModel notifications - notifying the processors about availability of a new JobModel.
- JobModel storage the coordination service dictates where the JobModel is persisted.
The coordination service is currently derived from the job coordinator factory. Samza ships with a ZkJobCoordinatorFactory implementation which has a corresponding ZkCoordinationServiceFactory.
Let’s walk through the coordination sequence for a ZooKeeper based embedded application:
- Each processor (participant) will register with the pluggable coordination service. During the registration it will provide its own participant ID.
- One of the participants will be elected as the leader.
- The leader monitors the list of all the active participants.
- Whenever the list of the participants changes, the leader will generate a new JobModel for the current participants.
- The new JobModel will be pushed to a common storage. The default implementation uses ZooKeeper for this purpose.
- Participants are notified that the new JobModel is available. Notification is done through the coordination services, e.g. ZooKeeper.
- The participants will stop processing, apply the new JobModel, and then resume processing.
The following diagram shows the relationships of the coordinators in the ZooKeeper coordination service implementation.
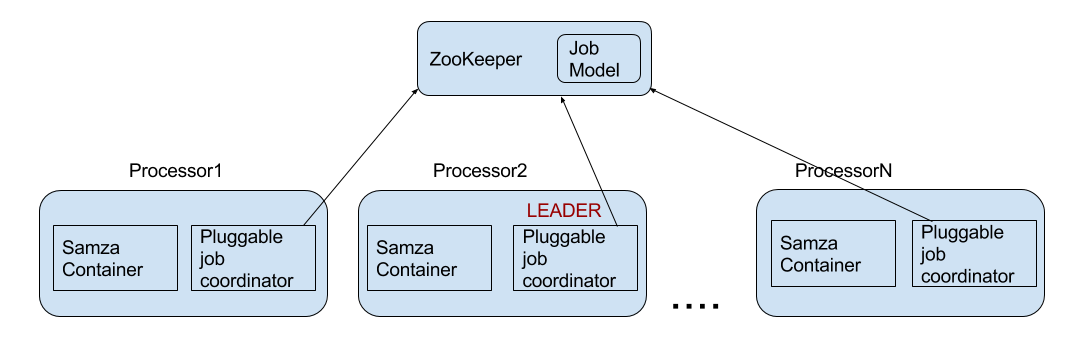
Here are a few important details about the coordination service:
- In order to ensure that no two partitions are processed twice by different processors, processing is paused and the processors synchronize on a barrier. Once all the processors are paused, the new JobModel is applied and the processing resumes. The barrier is implemented using the coordination service.
- During startup and shutdown the processors will be joining/leaving one after another. To avoid redundant JobModel re-calculation, there is a debounce timer which waits for some short period of time (2 seconds by default, configurable in a future release) for more processors to join or leave. Each time a processor joins or leaves, the timer is reset. When the timer expires the JobModel is finally recalculated.
- If the processors require local store for adjacent or temporary data, we would want to keep its mapping across restarts. For this we uses some extra information about each processor, which uniquely identifies it and its location. If the same processor is restarted on the same location we will try to assign it the same partitions. This locality information should survive the restarts, so it is stored on a common storage (currently using ZooKeeper).
User guide
Embedded deployment is designed to help users who want more control over the deployment of their application. So it is the user’s responsibility to configure and deploy the processors. In case of ZooKeeper coordination, you also need to configure the URL for an instance of ZooKeeper.
Additionally, each processor requires a unique ID to be used with the coordination service. If location affinity is important, this ID should be unique for each processor on a specific hostname (assuming local Storage services). To address this requirement, Samza uses a ProcessorIdGenerator to provide the ID for each processor. If no generator is explicitly configured, the default one will create a UUID for each processor.
Configuration
To run an embedded Samza processor, you need to configure the coordinator service using the job.coordinator.factory property. Also, there is currently one taskname grouper that supports embedded mode, so you must configure that explicitly.
Let’s take a look at how to configure the two coordination service implementations that ship with Samza.
To use ZooKeeper-based coordination, the following configs are required:
job.coordinator.factory=org.apache.samza.zk.ZkJobCoordinatorFactory
job.coordinator.zk.connect=yourzkconnection
task.name.grouper.factory=org.apache.samza.container.grouper.task.GroupByContainerIdsFactoryTo use external coordination, the following configs are needed:
job.coordinator.factory=org.apache.samza.standalone.PassthroughJobCoordinatorFactory
task.name.grouper.factory=org.apache.samza.container.grouper.task.GroupByContainerIdsFactoryAPI
As mentioned in the architecture section above, you use the LocalApplicationRunner to launch your processors from your application code, like this:
public class WikipediaZkLocalApplication {
public static void main(String[] args) {
CommandLine cmdLine = new CommandLine();
OptionSet options = cmdLine.parser().parse(args);
Config config = cmdLine.loadConfig(options);
LocalApplicationRunner runner = new LocalApplicationRunner(config);
WikipediaApplication app = new WikipediaApplication();
runner.run(app);
runner.waitForFinish();
}
}In the code above, WikipediaApplication is an application written with the high level API.
Check out the tutorial to run this application with ZooKeeper coordination on your machine now.
Deployment and Scaling
You can deploy the application instances in any way you prefer. If using the coordination service, you can add or remove instances at any time and the leader’s job coordinator (elected via the CoordinationService) will automatically recalculate the JobModel after the debounce time and apply it to the available processors. So, to scale up your application, you simply start more processors.
Known issues
Take note of the following issues with the embedded deployment feature for the 0.13.0 release. They will be fixed in a subsequent release.
- The GroupByContainerCount default taskname grouper isn’t supported.
- Host affinity is not enabled.
- ZkJobCoordinator metrics are not provided yet. Metrics will soon be added for
- Number of JobModel recalculations
- Number of Read/Writes
- Leader reelections
- more..
- The LocalApplicationRunner does not yet support the low level API. This means you cannot use StreamTask with LocalApplicationRunner.
- Currently, ‘app.id’ config must be unique for all the application using this zk cluster.