Core concepts
Introduction
Apache Samza is a scalable data processing engine that allows you to process and analyze your data in real-time. Here is a summary of Samza’s features that simplify building your applications:
Unified API: Use a simple API to describe your application-logic in a manner independent of your data-source. The same API can process both batch and streaming data.
Pluggability at every level: Process and transform data from any source. Samza offers built-in integrations with Apache Kafka, AWS Kinesis, Azure EventHubs, ElasticSearch and Apache Hadoop. Also, it’s quite easy to integrate with your own sources.
Samza as an embedded library: Integrate effortlessly with your existing applications eliminating the need to spin up and operate a separate cluster for stream processing. Samza can be used as a light-weight client-library embedded in your Java/Scala applications.
Write once, Run anywhere: Flexible deployment options to run applications anywhere - from public clouds to containerized environments to bare-metal hardware.
Samza as a managed service: Run stream-processing as a managed service by integrating with popular cluster-managers including Apache YARN.
Fault-tolerance: Transparently migrate tasks along with their associated state in the event of failures. Samza supports host-affinity and incremental checkpointing to enable fast recovery from failures.
Massive scale: Battle-tested on applications that use several terabytes of state and run on thousands of cores. It powers multiple large companies including LinkedIn, Uber, TripAdvisor, Slack etc.
Next, we will introduce Samza’s terminology. You will realize that it is extremely easy to get started with building your first application.
Streams, Partitions
Samza processes your data in the form of streams. A stream is a collection of immutable messages, usually of the same type or category. Each message in a stream is modelled as a key-value pair.
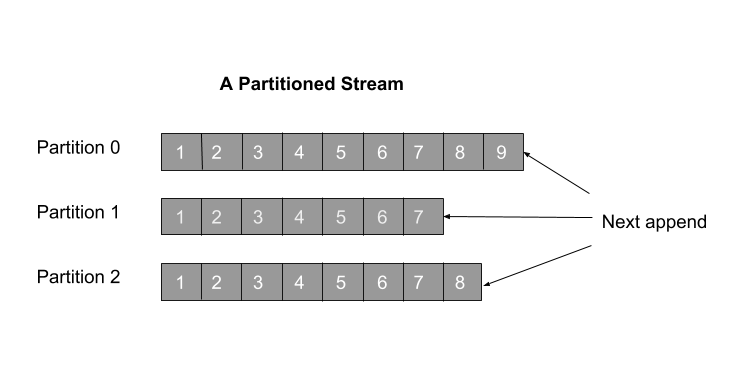
A stream can have multiple producers that write data to it and multiple consumers that read data from it. Data in a stream can be unbounded (eg: a Kafka topic) or bounded (eg: a set of files on HDFS).
A stream is sharded into multiple partitions for scaling how its data is processed. Each partition is an ordered, replayable sequence of records. When a message is written to a stream, it ends up in one of its partitions. Each message in a partition is uniquely identified by an offset.
Samza supports pluggable systems that can implement the stream abstraction. As an example, Kafka implements a stream as a topic while a database might implement a stream as a sequence of updates to its tables.
Stream Application
A stream application processes messages from input streams, transforms them and emits results to an output stream or a database. It is built by chaining multiple operators, each of which takes in one or more streams and transforms them.

Samza offers foure top-level APIs to help you build your stream applications:
- The High Level Streams API, which offers several built-in operators like map, filter, etc. This is the recommended API for most use-cases.
- The Low Level Task API, which allows greater flexibility to define your processing-logic and offers greater control
- Samza SQL, which offers a declarative SQL interface to create your applications
- Apache Beam API, which offers the full Java API from Apache beam while Python and Go are work-in-progress.
State
Samza supports both stateless and stateful stream processing. Stateless processing, as the name implies, does not retain any state associated with the current message after it has been processed. A good example of this is filtering an incoming stream of user-records by a field (eg:userId) and writing the filtered messages to their own stream.
In contrast, stateful processing requires you to record some state about a message even after processing it. Consider the example of counting the number of unique users to a website every five minutes. This requires you to store information about each user seen thus far for de-duplication. Samza offers a fault-tolerant, scalable state-store for this purpose.
Time
Time is a fundamental concept in stream processing, especially in how it is modeled and interpreted by the system. Samza supports two notions of time. By default, all built-in Samza operators use processing time. In processing time, the timestamp of a message is determined by when it is processed by the system. For example, an event generated by a sensor could be processed by Samza several milliseconds later.
On the other hand, in event time, the timestamp of an event is determined by when it actually occurred at the source. For example, a sensor which generates an event could embed the time of occurrence as a part of the event itself. Samza provides event-time based processing by its integration with Apache BEAM.
Processing guarantee
Samza supports at-least once processing. As the name implies, this ensures that each message in the input stream is processed by the system at-least once. This guarantees no data-loss even when there are failures, thereby making Samza a practical choice for building fault-tolerant applications.
Next Steps: We are now ready to have a closer look at Samza’s architecture.