slack.com
Building streaming data pipelines for monitoring and analytics at Slack
Slack is a cloud based company that offers collaboration tools and services to increase productivity. With a rapidly growing user base and a daily active users north of 8 million, they needed to react quickly to issues and proactively monitor the application health. For this, the team went on to build a new monitoring solution using Apache Samza with the following requirements:
- Near real-time alerting to quickly surface issues
- Fault-tolerant processing of data streams
- Process billions of events from metrics, logs and derive timely insights on application health
- Ease of extensibility to other use cases like experimentation
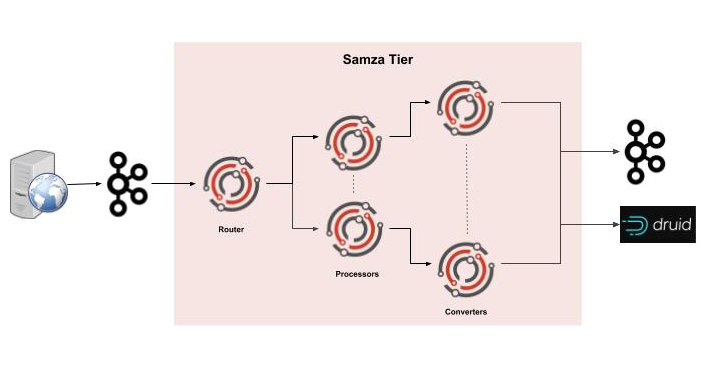
The engineering team at Slack built their data platform using Apache Samza. It has three types of Samza jobs - Routers, Processors and Converters.
All services at Slack emit their logs in a well-defined format, which end up in a Kafka cluster. The logs are processed by a fleet of Samza jobs called Routers. The routers deserialize incoming log events, decorate them and add instrumentation on top of them. The output of the router is processed by another pipeline, Processors which perform aggregations using Samza’s state-store. Finally, the processed results are enriched by the last stage - Coverters, which pipe the data into Druid for analytics and querying. Performance anomalies trigger an alert to a slackbot for further action. Slack built the data-platform to be extensible, thereby enabling other teams within the company to build their own applications on top of it.
Another noteworthy use-case powered by Samza is their experimentation framework. It leverages a data-pipeline to measure the results of A/B testing in near real-time. The pipeline uses Samza to join a stream of performance-related metrics with additional data on experiments that the customer was a part of. This enables Slack to learn how each experiment affects their overall customer experience.
Key Samza Features: Stateful processing, Join, Windowing
More information