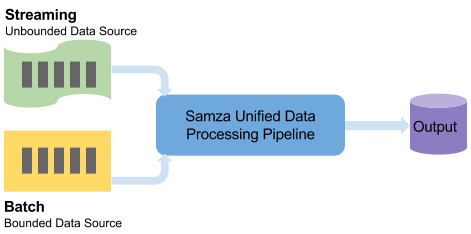
Batch Processing Overview
Samza provides a unified data processing model for both stream and batch processing. The primary difference between batch and streaming is whether the input size is bounded or unbounded. Batch data sources are typically bounded (e.g. static files on HDFS), whereas streams are unbounded (e.g. a topic in Kafka). Under the hood, the same highly-efficient stream-processing engine handles both types.
Unified API for Batch and Streaming
Samza provides a single set of APIs for both batch and stream processing. This unified programming API makes it convenient for you to focus on the processing logic, without treating bounded and unbounded sources differently. Switching between batch and streaming only requires config change, e.g. Kafka to HDFS, instead of any code change.
Multi-stage Batch Pipeline
Complex data pipelines usually consist multiple stages, with data shuffled (repartitioned) between stages to enable key-based operations such as windowing, aggregation, and join. Samza High Level Streams API provides an operator named partitionBy to create such multi-stage pipelines. Internally, Samza creates a physical stream, called an “intermediate stream”, based on the system configured as in job.default.system. Samza repartitions the output of the previous stage by sending it to the intermediate stream with the appropriate partition count and partition key. It then feeds it to the next stage of the pipeline. The lifecycle of intermediate streams is completely managed by Samza so from the user perspective the data shuffling is automatic.
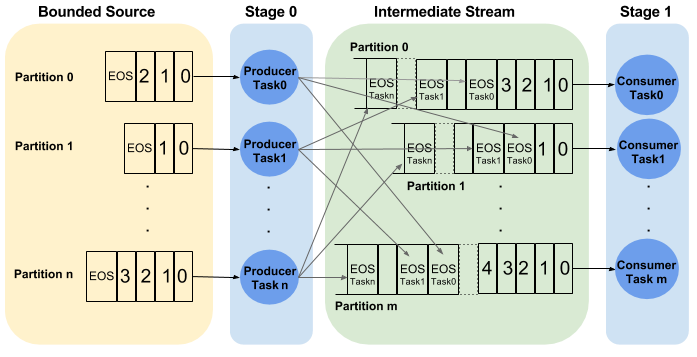
For a single-stage pipeline, dealing with bounded data sets is straightforward: the system consumer “knows” the end of a particular partition, and it will emit end-of-stream token once a partition is complete. Samza will shut down the container when all its input partitions are complete.
For a multi-stage pipeline, however, things become tricky since intermediate streams are often physically unbounded data streams, e.g. Kafka, and the downstream stages don’t know when to shut down since unbounded streams don’t have an end. To solve this problem, Samza uses in-band end-of-stream control messages in the intermediate stream along with user data messages. The upstream stage broadcasts end-of-stream control messages to every partition of the intermediate stream, and the downstream stage will aggregate the end-of-stream messages for each partition. When one end-of-stream message has been received for every upstream task in a partition, the downstream stage will conclude that the partition has no more messages, and the task will shut down. For pipelines with more than 2 stages, the end-of-stream control messages will be propagated from the source to the last stage, and each stage will perform the end-of-stream aggregation and then shuts down. The following diagram shows the flow:
State and Fault-tolerance
Samza’s state management and fault-tolerance apply the same to batch. You can use in-memory or RocksDb as your local state store which can be persisted by changelog streams. In case of any container failures, Samza will restart the container by reseeding the local store from changelog streams, and resume processing from the previous checkpoints.
During a job restart, batch processing behaves completely different from streaming. In batch, it is expected to be a re-run and all the internal streams, including intermediate, checkpoint and changelog streams, need to be fresh. Since some systems only support retention-based stream cleanup, e.g. Kafka without deletion enabled, Samza creates a new set of internal streams for each job run. To achieve this, Samza internally generates a unique run.id to each job run. The run.id is appended to the physical names of the internal streams, which will be used in the job in each run. Samza also performs due diligence to delete/purge the streams from previous run. The cleanup happens when the job is restarted.