Hello Samza High Level API - YARN Deployment
The hello-samza project is an example project designed to help you run your first Samza application. It has examples of applications using the Low Level Task API as well as the High Level Streams API.
This tutorial demonstrates a simple wikipedia application created with the High Level Streams API. The Hello Samza tutorial is the Low Level Task API analog to this tutorial. It demonstrates the same logic but is created with the Low Level Task API. The tutorials are designed to be as similar as possible. The primary differences are that with the High Level Streams API we accomplish the equivalent of 3 separate Low Level Task API jobs with a single application, we skip the intermediate topics for simplicity, and we can visualize the execution plan after we start the application.
Get the Code
Check out the hello-samza project:
git clone https://gitbox.apache.org/repos/asf/samza-hello-samza.git hello-samza
cd hello-samzaThis project contains everything you’ll need to run your first Samza application.
Start a Grid
A Samza grid usually comprises three different systems: YARN, Kafka, and ZooKeeper. The hello-samza project comes with a script called “grid” to help you setup these systems. Start by running:
./bin/grid bootstrapThis command will download, install, and start ZooKeeper, Kafka, and YARN. It will also check out the latest version of Samza and build it. All package files will be put in a sub-directory called “deploy” inside hello-samza’s root folder.
If you get a complaint that JAVA_HOME is not set, then you’ll need to set it to the path where Java is installed on your system.
Once the grid command completes, you can verify that YARN is up and running by going to http://localhost:8088. This is the YARN UI.
Build a Samza Application Package
Before you can run a Samza application, you need to build a package for it. This package is what YARN uses to deploy your apps on the grid.
NOTE: if you are building from the latest branch of hello-samza project, make sure that you run the following step from your local Samza project first:
./gradlew publishToMavenLocalThen, you can continue w/ the following command in hello-samza project:
mvn clean package
mkdir -p deploy/samza
tar -xvf ./target/hello-samza-1.6.0-dist.tar.gz -C deploy/samzaRun a Samza Application
After you’ve built your Samza package, you can start the app on the grid using the run-app.sh script.
./deploy/samza/bin/run-app.sh --config-path=$PWD/deploy/samza/config/wikipedia-application.propertiesThe app will do all of the following:
- Consume 3 feeds of real-time edits from Wikipedia
- Parse the events to extract information about the size of the edit, who made the change, etc.
- Calculate counts, every ten seconds, for all edits that were made during that window
- Output the counts to the wikipedia-stats topic
For details about how the app works, take a look at the code walkthrough.
Give the job a minute to startup, and then tail the Kafka topic:
./deploy/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wikipedia-statsThe messages in the stats topic look like this:
{"is-talk":2,"bytes-added":5276,"edits":13,"unique-titles":13}
{"is-bot-edit":1,"is-talk":3,"bytes-added":4211,"edits":30,"unique-titles":30,"is-unpatrolled":1,"is-new":2,"is-minor":7}
{"bytes-added":3180,"edits":19,"unique-titles":19,"is-unpatrolled":1,"is-new":1,"is-minor":3}
{"bytes-added":2218,"edits":18,"unique-titles":18,"is-unpatrolled":2,"is-new":2,"is-minor":3}Pretty neat, right? Now, check out the YARN UI again (http://localhost:8088). This time around, you’ll see your Samza job is running!
View the Execution Plan
Each application goes through an execution planner and you can visualize the execution plan after starting the job by opening the following file in a browser
deploy/samza/bin/plan.htmlThis plan will make more sense after the code walkthrough. For now, just take note that this visualization is available and it is useful for visibility into the structure of the application. For this tutorial, the plan should look something like this:
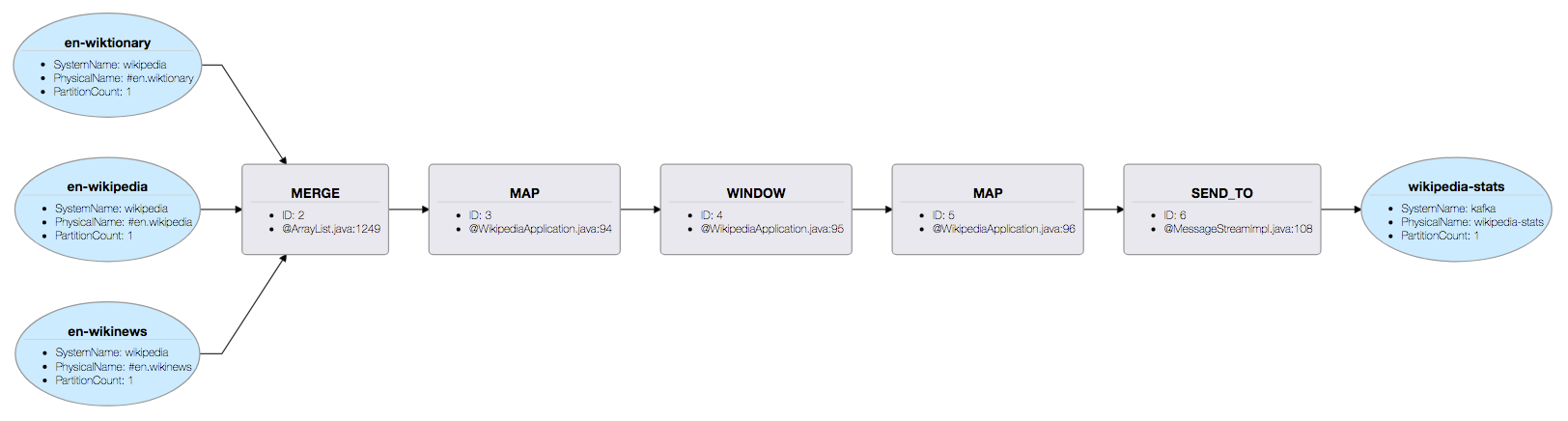
Shutdown
To shutdown the app, use the same run-app.sh script with an extra –operation=kill argument
./deploy/samza/bin/run-app.sh --config-path=$PWD/deploy/samza/config/wikipedia-application.properties --operation=killAfter you’re done, you can clean everything up using the same grid script.
./bin/grid stop allCongratulations! You’ve now setup a local grid that includes YARN, Kafka, and ZooKeeper, and run a Samza application on it. Curious how this application was built? See the code walk-through.