Architecture page
- Distributed execution
- Threading model and ordering
- Incremental checkpointing
- State management
- Fault tolerance of state
- Host affinity
Distributed execution
Task
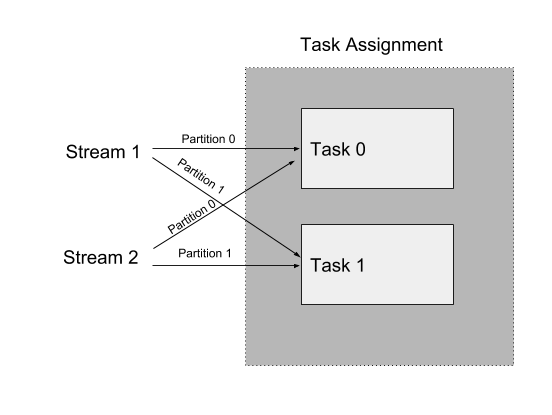
Samza scales your application by logically breaking it down into multiple tasks. A task is the unit of parallelism for your application. Each task consumes data from one partition of your input streams. The assignment of partitions to tasks never changes: if a task is on a machine that fails, the task is restarted elsewhere, still consuming the same stream partitions. Since there is no ordering of messages across partitions, it allows tasks to execute entirely independent of each other without sharing any state.
Container
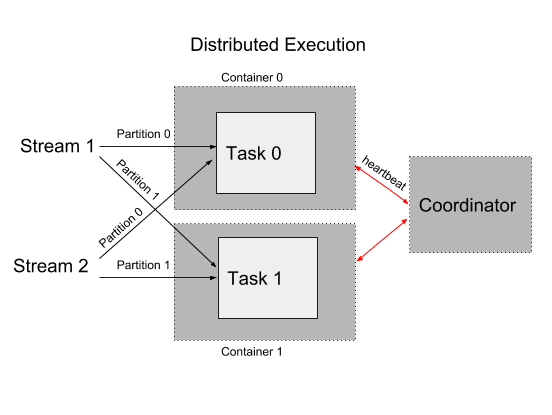
Just like a task is the logical unit of parallelism for your application, a container is the physical unit. You can think of each worker as a JVM process, which runs one or more tasks. An application typically has multiple containers distributed across hosts.
Coordinator
Each application also has a coordinator which manages the assignment of tasks across the individual containers. The coordinator monitors the liveness of individual containers and redistributes the tasks among the remaining ones during a failure.
The coordinator itself is pluggable, enabling Samza to support multiple deployment options. You can use Samza as a light-weight embedded library that easily integrates with a larger application. Alternately, you can deploy and run it as a managed framework using a cluster-manager like YARN. It is worth noting that Samza is the only system that offers first-class support for both these deployment options. Some systems like Kafka-streams only support the embedded library model while others like Flink, Spark streaming etc., only offer the framework model for stream-processing.
Threading model and ordering
Samza offers a flexible threading model to run each task. When running your applications, you can control the number of workers needed to process your data. You can also configure the number of threads each worker uses to run its assigned tasks. Each thread can run one or more tasks. Tasks don’t share any state - hence, you don’t have to worry about coordination across these threads.
Another common scenario in stream processing is to interact with remote services or databases. For example, a notifications system which processes each incoming message, generates an email and invokes a REST api to deliver it. Samza offers a fully asynchronous API for use-cases like this which require high-throughput remote I/O. s By default, all messages delivered to a task are processed by the same thread. This guarantees in-order processing of messages within a partition. However, some applications don’t care about in-order processing of messages. For such use-cases, Samza also supports processing messages out-of-order within a single partition. This typically offers higher throughput by allowing for multiple concurrent messages in each partition.
Incremental checkpointing
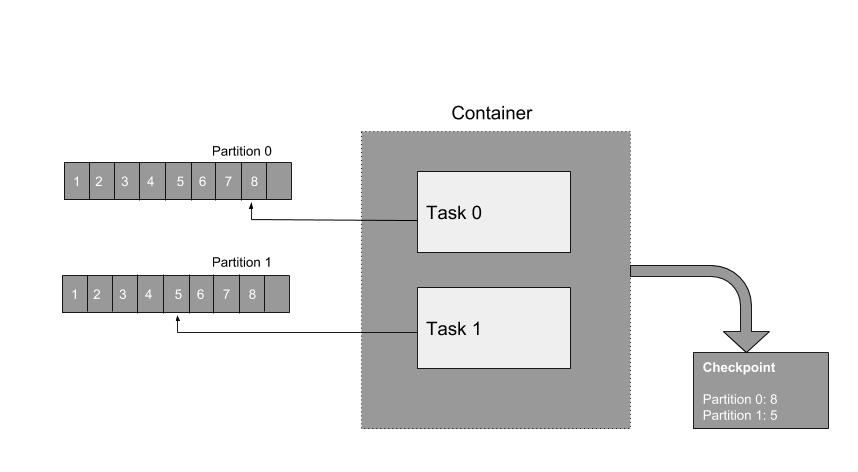
Samza guarantees that messages won’t be lost, even if your job crashes, if a machine dies, if there is a network fault, or something else goes wrong. To achieve this property, each task periodically persists the last processed offsets for its input stream partitions. If a task needs to be restarted on a different worker due to a failure, it resumes processing from its latest checkpoint.
Samza’s checkpointing mechanism ensures each task also stores the contents of its state-store consistently with its last processed offsets. Checkpoints are flushed incrementally ie., the state-store only flushes the delta since the previous checkpoint instead of flushing its entire state.
State management
Samza offers scalable, high-performance storage to enable you to build stateful stream-processing applications. This is implemented by associating each Samza task with its own instance of a local database (aka. a state-store). The state-store associated with a particular task only stores data corresponding to the partitions processed by that task. This is important: when you scale out your job by giving it more computing resources, Samza transparently migrates the tasks from one machine to another. By giving each task its own state, tasks can be relocated without affecting your overall application.
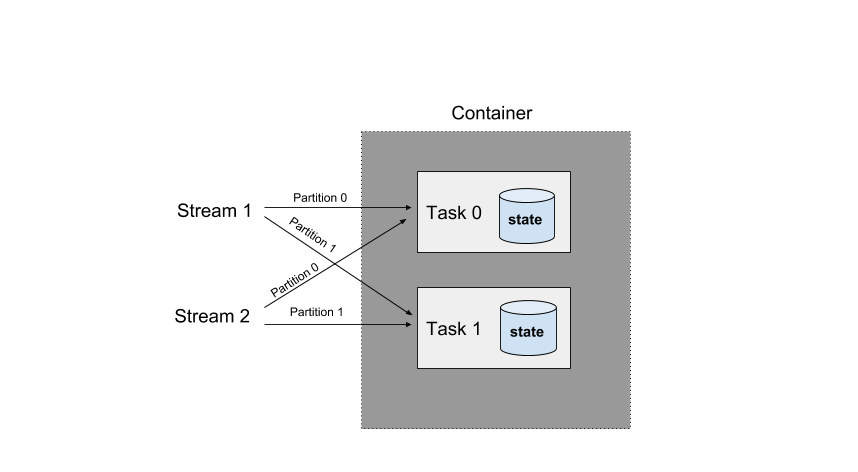
Here are some key advantages of this architecture.
- The state is stored on disk, so the job can maintain more state than would fit in memory.
- It is stored on the same machine as the task, to avoid the performance problems of making database queries over the network.
- Each job has its own store, to avoid the isolation issues in a shared remote database (if you make an expensive query, it affects only the current task, nobody else).
- Different storage engines can be plugged in - for example, a remote data-store that enables richer query capabilities
Fault tolerance of state
Distributed stream processing systems need recover quickly from failures to resume their processing. While having a durable local store offers great performance, we should still guarantee fault-tolerance. For this purpose, Samza replicates every change to the local store into a separate stream (aka. called a changelog for the store). This allows you to later recover the data in the store by reading the contents of the changelog from the beginning. A log-compacted Kafka topic is typically used as a changelog since Kafka automatically retains the most recent value for each key.
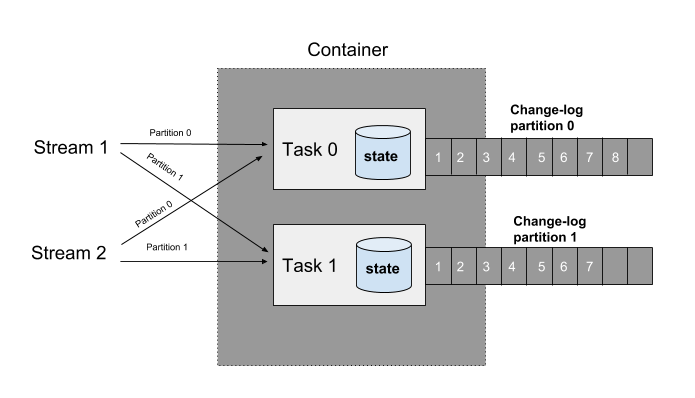
Host affinity
If your application has several terabytes of state, then bootstrapping it every time by reading the changelog will stall progress. So, it’s critical to be able to recover state swiftly during failures. For this purpose, Samza takes data-locality into account when scheduling tasks on hosts. This is implemented by persisting metadata about the host each task is currently running on.
During a new deployment of the application, Samza tries to re-schedule the tasks on the same hosts they were previously on. This enables the task to re-use the snapshot of its local-state from its previous run on that host. We call this feature host-affinity since it tries to preserve the assignment of tasks to hosts. This is a key differentiator that enables Samza applications to scale to several terabytes of local-state with effectively zero downtime.