Application Master
YARN is Hadoop’s next-generation cluster manager. It allows developers to deploy and execute arbitrary commands on a grid. If you’re unfamiliar with YARN, or the concept of an ApplicationMaster (AM), please read Hadoop’s YARN page.
Integration
Samza’s main integration with YARN comes in the form of a Samza ApplicationMaster. This is the chunk of code responsible for managing a Samza job in a YARN grid. It decides what to do when a stream processor fails, which machines a Samza job’s containers should run on, and so on.
When the Samza ApplicationMaster starts up, it does the following:
- Receives configuration from YARN via the STREAMING_CONFIG environment variable.
- Starts a JMX server on a random port.
- Instantiates a metrics registry and reporters to keep track of relevant metrics.
- Registers the AM with YARN’s RM.
- Get the total number of partitions for the Samza job using each input stream’s PartitionManager (see the Streams page for details).
- Read the total number of containers requested from the Samza job’s configuration.
- Assign each partition to a container (called a Task Group in Samza’s AM dashboard).
- Make a ResourceRequest to YARN for each container.
- Poll the YARN RM every second to check for allocated and released containers.
From this point on, the ApplicationMaster just reacts to events from the RM.
Fault Tolerance
Whenever a container is allocated, the AM will work with the YARN NM to start a SamzaContainer (with appropriate partitions assigned to it) in the container. If a container fails with a non-zero return code, the AM will request a new container, and restart the SamzaContainer. If a SamzaContainer fails too many times, too quickly, the ApplicationMaster will fail the whole Samza job with a non-zero return code. See the yarn.container.retry.count and yarn.container.retry.window.ms configuration parameters for details.
When the AM receives a reboot signal from YARN, it will throw a SamzaException. This will trigger a clean and successful shutdown of the AM (YARN won’t think the AM failed).
If the AM, itself, fails, YARN will handle restarting the AM. When the AM is restarted, all containers that were running will be killed, and the AM will start from scratch. The same list of operations, shown above, will be executed. The AM will request new containers for its SamzaContainers, and proceed as though it has just started for the first time. YARN has a yarn.resourcemanager.am.max-retries configuration parameter that’s defined in yarn-site.xml. This configuration defaults to 1, which means that, by default, a single AM failure will cause your Samza job to stop running.
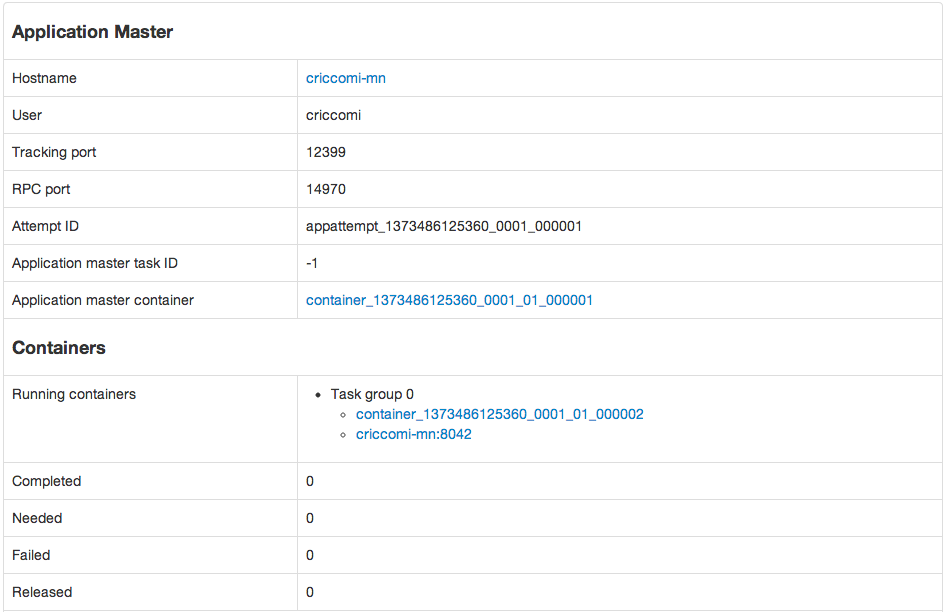
Dashboard
Samza’s ApplicationMaster comes with a dashboard to show useful information such as:
- Where containers are located.
- Links to logs.
- The Samza job’s configuration.
- Container failure count.
You can find this dashboard by going to your YARN grid’s ResourceManager page (usually something like http://localhost:8088/cluster), and clicking on the “ApplicationMaster” link of a running Samza job.
Security
The Samza dashboard’s HTTP access is currently un-secured, even when using YARN in secure-mode. This means that users with access to a YARN grid could port-scan a Samza ApplicationMaster’s HTTP server, and open the dashboard in a browser to view its contents. Sensitive configuration can be viewed by anyone, in this way, and care should be taken. There are plans to secure Samza’s ApplicationMaster using Hadoop’s security features (SPENAGO).
See Samza’s security page for more details.