Concepts
This page gives an introduction to the high-level concepts in Samza.
Streams
Samza processes streams. A stream is composed of immutable messages of a similar type or category. For example, a stream could be all the clicks on a website, or all the updates to a particular database table, or all the logs produced by a service, or any other type of event data. Messages can be appended to a stream or read from a stream. A stream can have any number of consumers, and reading from a stream doesn’t delete the message (so each message is effectively broadcast to all consumers). Messages can optionally have an associated key which is used for partitioning, which we’ll talk about in a second.
Samza supports pluggable systems that implement the stream abstraction: in Kafka a stream is a topic, in a database we might read a stream by consuming updates from a table, in Hadoop we might tail a directory of files in HDFS.
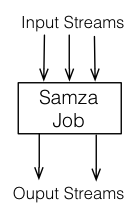
Jobs
A Samza job is code that performs a logical transformation on a set of input streams to append output messages to set of output streams.
If scalability were not a concern, streams and jobs would be all we need. However, in order to scale the throughput of the stream processor, we chop streams and jobs up into smaller units of parallelism: partitions and tasks.
Partitions
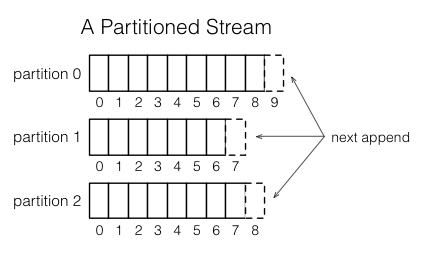
Each stream is broken into one or more partitions. Each partition in the stream is a totally ordered sequence of messages.
Each message in this sequence has an identifier called the offset, which is unique per partition. The offset can be a sequential integer, byte offset, or string depending on the underlying system implementation.
When a message is appended to a stream, it is appended to only one of the stream’s partitions. The assignment of the message to its partition is done with a key chosen by the writer. For example, if the user ID is used as the key, that ensures that all messages related to a particular user end up in the same partition.
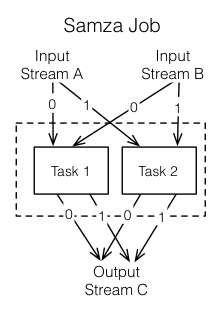
Tasks
A job is scaled by breaking it into multiple tasks. The task is the unit of parallelism of the job, just as the partition is to the stream. Each task consumes data from one partition for each of the job’s input streams.
A task processes messages from each of its input partitions sequentially, in the order of message offset. There is no defined ordering across partitions. This allows each task to operate independently. The YARN scheduler assigns each task to a machine, so the job as a whole can be distributed across many machines.
The number of tasks in a job is determined by the number of input partitions (there cannot be more tasks than input partitions, or there would be some tasks with no input). However, you can change the computational resources assigned to the job (the amount of memory, number of CPU cores, etc.) to satisfy the job’s needs. See notes on containers below.
The assignment of partitions to tasks never changes: if a task is on a machine that fails, the task is restarted elsewhere, still consuming the same stream partitions.
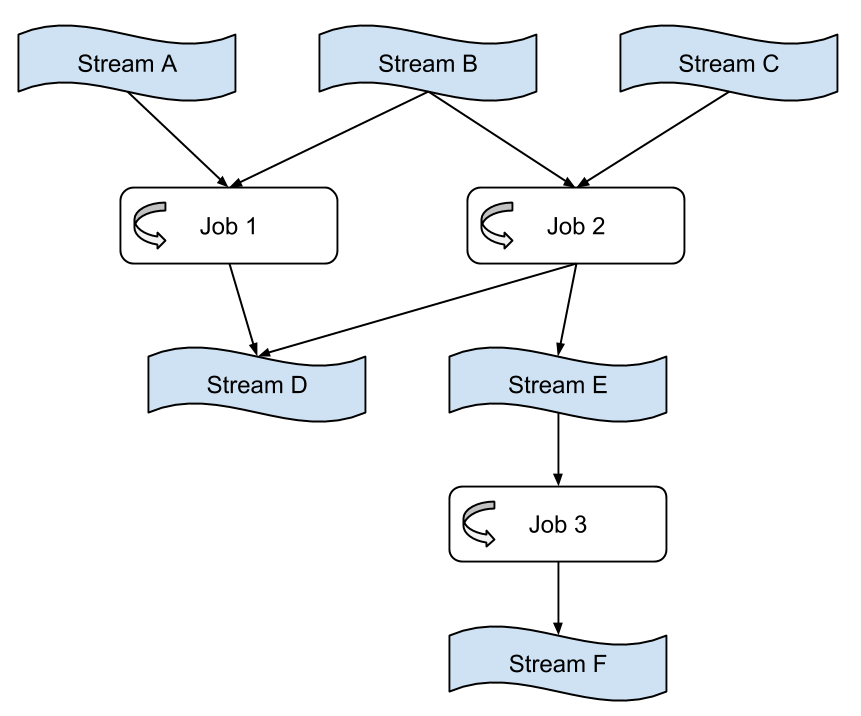
Dataflow Graphs
We can compose multiple jobs to create a dataflow graph, where the nodes are streams containing data, and the edges are jobs performing transformations. This composition is done purely through the streams the jobs take as input and output. The jobs are otherwise totally decoupled: they need not be implemented in the same code base, and adding, removing, or restarting a downstream job will not impact an upstream job.
These graphs are often acyclic—that is, data usually doesn’t flow from a job, through other jobs, back to itself. However, it is possible to create cyclic graphs if you need to.
Containers
Partitions and tasks are both logical units of parallelism—they don’t correspond to any particular assignment of computational resources (CPU, memory, disk space, etc). Containers are the unit of physical parallelism, and a container is essentially a Unix process (or Linux cgroup). Each container runs one or more tasks. The number of tasks is determined automatically from the number of partitions in the input and is fixed, but the number of containers (and the CPU and memory resources associated with them) is specified by the user at run time and can be changed at any time.