Architecture
Samza is made up of three layers:
- A streaming layer.
- An execution layer.
- A processing layer.
Samza provides out of the box support for all three layers.
These three pieces fit together to form Samza:
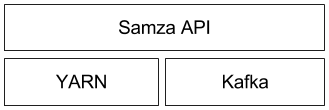
This architecture follows a similar pattern to Hadoop (which also uses YARN as execution layer, HDFS for storage, and MapReduce as processing API):
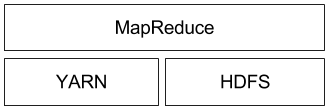
Before going in-depth on each of these three layers, it should be noted that Samza’s support is not limited to Kafka and YARN. Both Samza’s execution and streaming layer are pluggable, and allow developers to implement alternatives if they prefer.
Kafka
Kafka is a distributed pub/sub and message queueing system that provides at-least once messaging guarantees (i.e. the system guarantees that no messages are lost, but in certain fault scenarios, a consumer might receive the same message more than once), and highly available partitions (i.e. a stream’s partitions continue to be available even if a machine goes down).
In Kafka, each stream is called a topic. Each topic is partitioned and replicated across multiple machines called brokers. When a producer sends a message to a topic, it provides a key, which is used to determine which partition the message should be sent to. The Kafka brokers receive and store the messages that the producer sends. Kafka consumers can then read from a topic by subscribing to messages on all partitions of a topic.
Kafka has some interesting properties:
- All messages with the same key are guaranteed to be in the same topic partition. This means that if you wish to read all messages for a specific user ID, you only have to read the messages from the partition that contains the user ID, not the whole topic (assuming the user ID is used as key).
- A topic partition is a sequence of messages in order of arrival, so you can reference any message in the partition using a monotonically increasing offset (like an index into an array). This means that the broker doesn’t need to keep track of which messages have been seen by a particular consumer — the consumer can keep track itself by storing the offset of the last message it has processed. It then knows that every message with a lower offset than the current offset has already been processed; every message with a higher offset has not yet been processed.
For more details on Kafka, see Kafka’s documentation pages.
YARN
YARN (Yet Another Resource Negotiator) is Hadoop’s next-generation cluster scheduler. It allows you to allocate a number of containers (processes) in a cluster of machines, and execute arbitrary commands on them.
When an application interacts with YARN, it looks something like this:
- Application: I want to run command X on two machines with 512MB memory.
- YARN: Cool, where’s your code?
- Application: http://path.to.host/jobs/download/my.tgz
- YARN: I’m running your job on node-1.grid and node-2.grid.
Samza uses YARN to manage deployment, fault tolerance, logging, resource isolation, security, and locality. A brief overview of YARN is below; see this page from Hortonworks for a much better overview.
YARN Architecture
YARN has three important pieces: a ResourceManager, a NodeManager, and an ApplicationMaster. In a YARN grid, every machine runs a NodeManager, which is responsible for launching processes on that machine. A ResourceManager talks to all of the NodeManagers to tell them what to run. Applications, in turn, talk to the ResourceManager when they wish to run something on the cluster. The third piece, the ApplicationMaster, is actually application-specific code that runs in the YARN cluster. It’s responsible for managing the application’s workload, asking for containers (usually UNIX processes), and handling notifications when one of its containers fails.
Samza and YARN
Samza provides a YARN ApplicationMaster and a YARN job runner out of the box. The integration between Samza and YARN is outlined in the following diagram (different colors indicate different host machines):
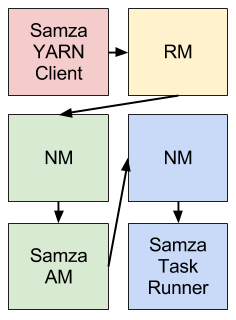
The Samza client talks to the YARN RM when it wants to start a new Samza job. The YARN RM talks to a YARN NM to allocate space on the cluster for Samza’s ApplicationMaster. Once the NM allocates space, it starts the Samza AM. After the Samza AM starts, it asks the YARN RM for one or more YARN containers to run SamzaContainers. Again, the RM works with NMs to allocate space for the containers. Once the space has been allocated, the NMs start the Samza containers.
Samza
Samza uses YARN and Kafka to provide a framework for stage-wise stream processing and partitioning. Everything, put together, looks like this (different colors indicate different host machines):
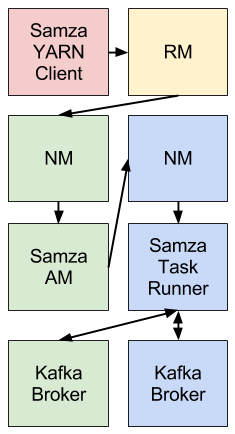
The Samza client uses YARN to run a Samza job: YARN starts and supervises one or more SamzaContainers, and your processing code (using the StreamTask API) runs inside those containers. The input and output for the Samza StreamTasks come from Kafka brokers that are (usually) co-located on the same machines as the YARN NMs.
Example
Let’s take a look at a real example: suppose we want to count the number of page views. In SQL, you would write something like:
SELECT user_id, COUNT(*) FROM PageViewEvent GROUP BY user_id
Although Samza doesn’t support SQL right now, the idea is the same. Two jobs are required to calculate this query: one to group messages by user ID, and the other to do the counting.
In the first job, the grouping is done by sending all messages with the same user ID to the same partition of an intermediate topic. You can do this by using the user ID as key of the messages that are emitted by the first job, and this key is mapped to one of the intermediate topic’s partitions (usually by taking a hash of the key mod the number of partitions). The second job consumes the intermediate topic. Each task in the second job consumes one partition of the intermediate topic, i.e. all the messages for a subset of user IDs. The task has a counter for each user ID in its partition, and the appropriate counter is incremented every time the task receives a message with a particular user ID.
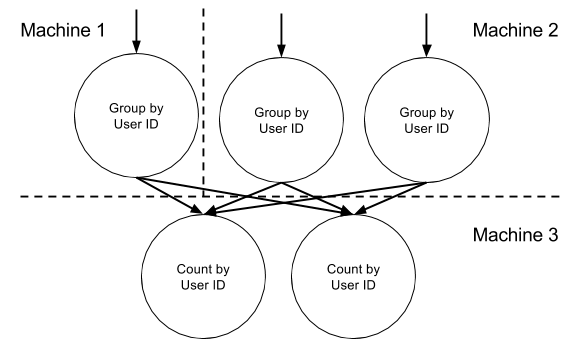
If you are familiar with Hadoop, you may recognize this as a Map/Reduce operation, where each record is associated with a particular key in the mappers, records with the same key are grouped together by the framework, and then counted in the reduce step. The difference between Hadoop and Samza is that Hadoop operates on a fixed input, whereas Samza works with unbounded streams of data.
Kafka takes the messages emitted by the first job and buffers them on disk, distributed across multiple machines. This helps make the system fault-tolerant: if one machine fails, no messages are lost, because they have been replicated to other machines. And if the second job goes slow or stops consuming messages for any reason, the first job is unaffected: the disk buffer can absorb the backlog of messages from the first job until the second job catches up again.
By partitioning topics, and by breaking a stream process down into jobs and parallel tasks that run on multiple machines, Samza scales to streams with very high message throughput. By using YARN and Kafka, Samza achieves fault-tolerance: if a process or machine fails, it is automatically restarted on another machine and continues processing messages from the point where it left off.