Host Affinity & YARN
In Samza, containers are the units of physical parallelism that runs on a set of machines. Each container is essentially a process that runs one or more stream tasks. Each task instance consumes one or more partitions of the input streams and is associated with its own durable data store.
We define a Stateful Samza Job as the Samza job that uses a key-value store in its implementation, along with an associated changelog stream. In stateful samza jobs, a task may be configured to use multiple stores. For each store there is a 1:1 mapping between the task instance and the data store. Since the allocation of containers to machines in the Yarn cluster is completely left to Yarn, Samza does not guarantee that a container (and hence, its associated task(s)) gets deployed on the same machine. Containers can get shuffled in any of the following cases:
- When a job is upgraded by pointing
yarn.package.pathto the new package path and re-submitted. - When a job is simply restarted by Yarn or the user
- When a container failure or premption triggers the SamzaAppMaster to re-allocate on another available resource
In any of the above cases, the task’s co-located data needs to be restored every time a container starts-up. Restoring data each time can be expensive, especially for applications that have a large data set. This behavior slows the start-up time for the job so much that the job is no longer “near realtime”. Furthermore, if multiple stateful samza jobs restart around the same time in the cluster and they all share the same changelog system, then it is possible to quickly saturate the changelog system’s network and cause a DDoS.
For instance, consider a Samza job performing a Stream-Table join. Typically, such a job requires the dataset to be available on all processors before they begin processing the input stream. The dataset is usually large (order > 1TB) read-only data that will be used to join or add attributes to incoming messages. The job may initialize this cache by populating it with data directly from a remote store or changelog stream. This cache initialization happens each time the container is restarted. This causes significant latency during job start-up.
The solution, then, is to simply persist the state store on the machine in which the container process is executing and re-allocate the same host for the container each time the job is restarted, in order to re-use the persisted state. Thus, the ability of Samza to allocate a container to the same machine across job restarts is referred to as host-affinity. Samza leverages host-affinity to enhance our support for local state re-use.
How does it work?
When a stateful Samza job is deployed in Yarn, the state stores for the tasks are co-located in the current working directory of Yarn’s application attempt.
container_working_dir=${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/application_${appid}/container_${contid}/
# Data Stores
ls ${container_working_dir}/state/${store-name}/${task_name}/This allows the Node Manager’s (NM) DeletionService to clean-up the working directory once the application completes or fails. In order to re-use local state store, the state store needs to be persisted outside the scope of NM’s deletion service. The cluster administrator should set this location as an environment variable in Yarn - LOGGED_STORE_BASE_DIR.
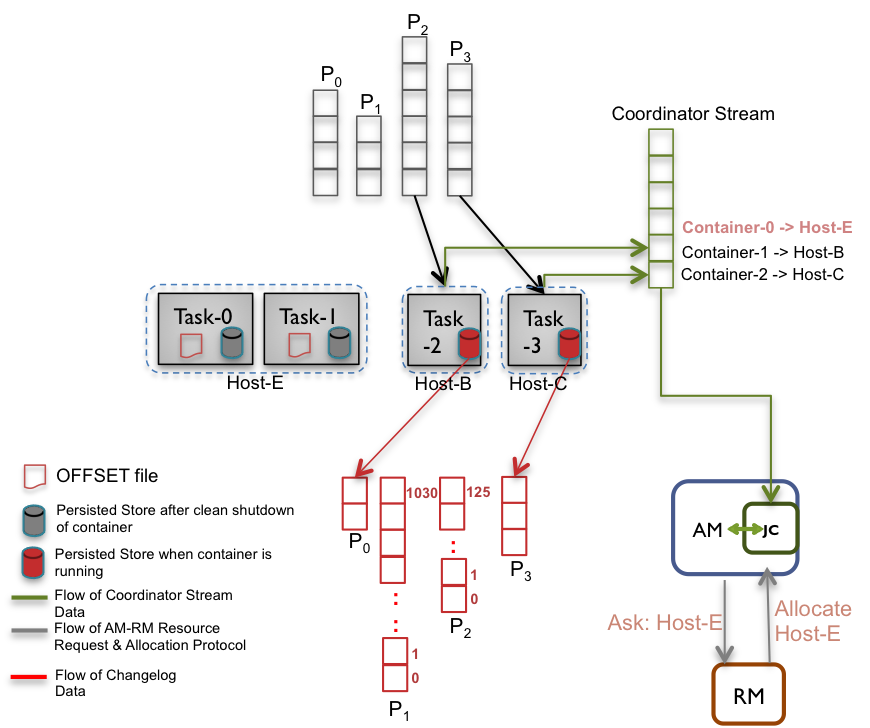
Each time a task commits, Samza writes the last materialized offset from the changelog stream to the checksumed file on disk. This is also done on container shutdown. Thus, there is an OFFSET file associated with each state stores' changelog partitions, that is consumed by the tasks in the container.
${LOGGED_STORE_BASE_DIR}/${job.name}-${job.id}/${store.name}/${task.name}/OFFSETNow, when a container restarts on the same machine after the OFFSET file exists, the Samza container:
- Opens the persisted store on disk
- Reads the OFFSET file
- Restores the state store from the OFFSET value
This significantly reduces the state restoration time on container start-up as we no longer consume from the beginning of the changelog stream. If the OFFSET file doesn’t exist, it creates the state store and consumes from the oldest offset in the changelog to re-create the state. Since the OFFSET file is written on each commit after flushing the store, the recorded offset is guaranteed to correspond to the current contents of the store or some older point, but never newer. This gives at least once semantics for state restore. Therefore, the changelog entries must be idempotent.
It is necessary to periodically clean-up unused or orphaned state stores on the machines to manage disk-space. This feature is being worked on in SAMZA-656.
In order to re-use local state, Samza has to sucessfully claim the specific hosts from the Resource Manager (RM). To support this, the Samza containers write their locality information to the Coordinator Stream every time they start-up successfully. Now, the Samza Application Master (AM) can identify the last known host of a container via the Job Coordinator(JC) and the application is no longer agnostic of the container locality. On a container failure (due to any of the above cited reasons), the AM includes the hostname of the expected resource in the ResourceRequest.
Note that the Yarn cluster has to be configured to use Fair Scheduler with continuous-scheduling enabled. With continuous scheduling, the scheduler continuously iterates through all nodes in the cluster, instead of relying on the nodes' heartbeat, and schedules work based on previously known status for each node, before relaxing locality. Hence, the scheduler takes care of relaxing locality after the configured delay. This approach can be considered as a “best-effort stickiness” policy because it is possible that the requested node is not running or does not have sufficient resources at the time of request (even though the state in the data stores may be persisted). For more details on the choice of Fair Scheduler, please refer the design doc.
Configuring YARN cluster to support Host Affinity
- Enable local state re-use by setting the
LOGGED_STORE_BASE_DIRenvironment variable in yarn-env.shWithout this configuration, the state stores are not persisted upon a container shutdown. This will effectively mean you will not re-use local state and hence, host-affinity becomes a moot operation.export LOGGEDSTOREBASE_DIR=<path-for-state-stores> Configure Yarn to use Fair Scheduler and enable continuous-scheduling in yarn-site.xml
<property> <name>yarn.resourcemanager.scheduler.class</name> <description>The class to use as the resource scheduler.</description> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> </property> <property> <name>yarn.scheduler.fair.continuous-scheduling-enabled</name> <description>Enable Continuous Scheduling of Resource Requests</description> <value>true</value> </property> <property> <name>yarn.scheduler.fair.locality-delay-node-ms</name> <description>Delay time in milliseconds before relaxing locality at node-level</description> <value>1000</value> <!-- Should be tuned per requirement --> </property> <property> <name>yarn.scheduler.fair.locality-delay-rack-ms</name> <description>Delay time in milliseconds before relaxing locality at rack-level</description> <value>1000</value> <!-- Should be tuned per requirement --> </property>Configure Yarn Node Manager SIGTERM to SIGKILL timeout to be reasonable time s.t. Node Manager will give Samza Container enough time to perform a clean shutdown in yarn-site.xml
<property> <name>yarn.nodemanager.sleep-delay-before-sigkill.ms</name> <description>No. of ms to wait between sending a SIGTERM and SIGKILL to a container</description> <value>600000</value> <!-- Set it to 10min to allow enough time for clean shutdown of containers --> </property>The Yarn Rack Awareness feature is not required and does not change the behavior of Samza Host Affinity. However, if Rack Awareness is configured in the cluster, make sure the DNSToSwitchMapping implementation is robust. Any failures could cause container requests to fall back to the defaultRack. This will cause ContainerRequests to not match the preferred host, which will degrade Host Affinity. For details, see SAMZA-866
Configuring a Samza job to use Host Affinity
Any stateful Samza job can leverage this feature to reduce the Mean Time To Restore (MTTR) of its state stores by setting yarn.samza.host-affinity.enabled to true.
yarn.samza.host-affinity.enabled=true # Default: falseEnabling this feature for a stateless Samza job should not have any adverse effect on the job.
Host-affinity Guarantees
As you have observed, host-affinity cannot be guaranteed all the time due to varibale load distribution in the Yarn cluster. Hence, this is a best-effort policy that Samza provides. However, certain scenarios are worth calling out where these guarantees may be hard to achieve or are not applicable.
- When the number of containers and/or container-task assignment changes across successive application runs - We may be able to re-use local state for a subset of partitions. Currently, there is no logic in the Job Coordinator to handle partitioning of tasks among containers intelligently. Handling this is more involved as relates to auto-scaling of the containers. However, with task-container mapping, this will work better for typical container count adjustments.
- When SystemStreamPartitionGrouper changes across successive application runs - When the grouper logic used to distribute the partitions across containers changes, the data in the Coordinator Stream (for changelog-task partition assignment etc) and the data stores becomes invalid. Thus, to be safe, we should flush out all state-related data from the Coordinator Stream. An alternative is to overwrite the Task-ChangelogPartition assignment message and the Container Locality message in the Coordinator Stream, before starting up the job again.